VPP-221 CLI auto-documentation infrastructure
As a step before Doxygen, extract CLI-related struct initializers
from the code and parse that into a summary of the CLI commands
available with the provided help text, such as it is. At the moment
this only renders this into an indexed Markdown file that Doxygen
then picks up but later we can use this information to enrich the
existing VLIB_CLI_COMMAND macro documentor as well as provide
runtime documentation to VPP that is stored on disk outside the
binary image.
Additionally support a comment block immediately prior to
VLIB_CLI_COMMAND CLI command definitions in the form /*? ... ?*/
that can be used to include long-form documentation without having
it compiled into VPP.
Examples of documenting CLI commands can be found in
vlib/vlib/unix/cli.c which, whilst not perfect, should provide a
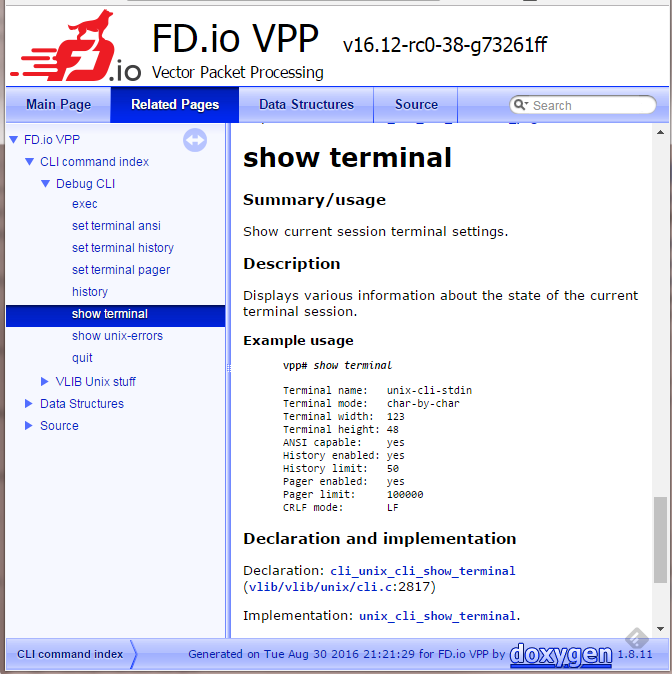
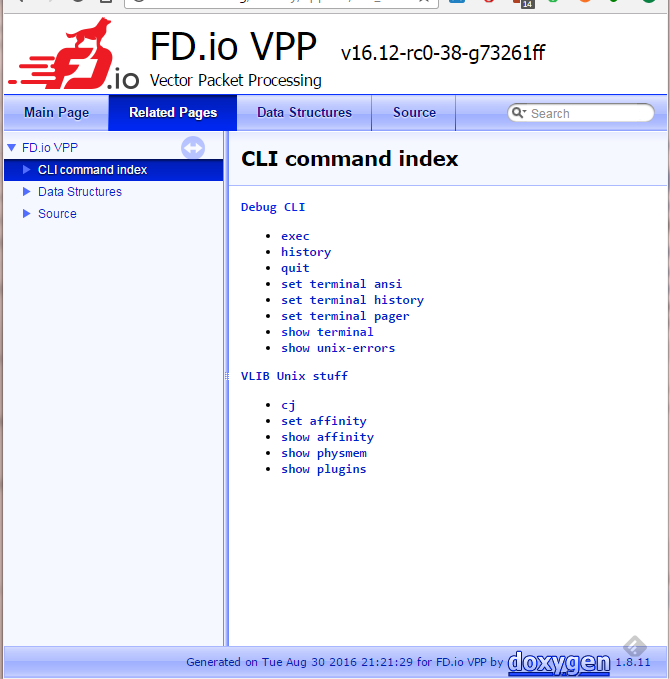
starting point. Screen captures of sample output can be seen at
https://chrisy.flirble.org/vpp/doxy-cli-example.png and
https://chrisy.flirble.org/vpp/doxy-cli-index.png .
Next, shift the Doxygen root makefile targets to their own Makefile.
The primary reason for this is that the siphon targets do dependency
tracking which means it needs to generate those dependencies whenever
make is run; that is pointless if we're not going to generate any
documentation. This includes the package dependencies since they since
they sometimes unnecessarily interfere with the code build in some cases
at the moment; later we will look to building a Python venv to host the
Python modules we use.
One final remark: In future we may consider deprecating .long_help
in the VLIB_CLI_COMMAND structure entirely but add perhaps .usage_help.
.short_help would be reserved for a summary of the command function
and .usage_help provide the syntax of that command. These changes would
provide great semantic value to the automaticly generated CLI
documentation. I could also see having .long_help replaced by a
mechanism that reads it from disk at runtime with a rudimentary
Markdown/Doxygen filter so that we can use the same text that is used in
the published documentation.
Change-Id: I80d6fe349b47dce649fa77d21ffec0ddb45c7bbf
Signed-off-by: Chris Luke <chrisy@flirble.org>
diff --git a/doxygen/siphon_process.py b/doxygen/siphon_process.py
new file mode 100755
index 0000000..80add4b
--- /dev/null
+++ b/doxygen/siphon_process.py
@@ -0,0 +1,323 @@
+#!/usr/bin/env python
+# Copyright (c) 2016 Comcast Cable Communications Management, LLC.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at:
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Filter for .siphon files that are generated by other filters.
+# The idea is to siphon off certain initializers so that we can better
+# auto-document the contents of that initializer.
+
+import os, sys, re, argparse, cgi, json
+import pyparsing as pp
+
+import pprint
+
+DEFAULT_SIPHON ="clicmd"
+DEFAULT_OUTPUT = None
+DEFAULT_PREFIX = os.getcwd()
+
+siphon_map = {
+ 'clicmd': "VLIB_CLI_COMMAND",
+}
+
+ap = argparse.ArgumentParser()
+ap.add_argument("--type", '-t', metavar="siphon_type", default=DEFAULT_SIPHON,
+ choices=siphon_map.keys(),
+ help="Siphon type to process [%s]" % DEFAULT_SIPHON)
+ap.add_argument("--output", '-o', metavar="directory", default=DEFAULT_OUTPUT,
+ help="Output directory for .md files [%s]" % DEFAULT_OUTPUT)
+ap.add_argument("--input-prefix", metavar="path", default=DEFAULT_PREFIX,
+ help="Prefix to strip from input pathnames [%s]" % DEFAULT_PREFIX)
+ap.add_argument("input", nargs='+', metavar="input_file",
+ help="Input .siphon files")
+args = ap.parse_args()
+
+if args.output is None:
+ sys.stderr.write("Error: Siphon processor requires --output to be set.")
+ sys.exit(1)
+
+
+def clicmd_index_sort(cfg, group, dec):
+ if group in dec and 'group_label' in dec[group]:
+ return dec[group]['group_label']
+ return group
+
+def clicmd_index_header(cfg):
+ s = "# CLI command index\n"
+ s += "\n[TOC]\n"
+ return s
+
+def clicmd_index_section(cfg, group, md):
+ return "\n@subpage %s\n\n" % md
+
+def clicmd_index_entry(cfg, meta, item):
+ v = item["value"]
+ return "* [%s](@ref %s)\n" % (v["path"], meta["label"])
+
+def clicmd_sort(cfg, meta, item):
+ return item['value']['path']
+
+def clicmd_header(cfg, group, md, dec):
+ if group in dec and 'group_label' in dec[group]:
+ label = dec[group]['group_label']
+ else:
+ label = group
+ return "\n@page %s %s\n" % (md, label)
+
+def clicmd_format(cfg, meta, item):
+ v = item["value"]
+ s = "\n@section %s %s\n" % (meta['label'], v['path'])
+
+ # The text from '.short_help = '.
+ # Later we should split this into short_help and usage_help
+ # since the latter is how it is primarily used but the former
+ # is also needed.
+ if "short_help" in v:
+ tmp = v["short_help"].strip()
+
+ # Bit hacky. Add a trailing period if it doesn't have one.
+ if tmp[-1] != ".":
+ tmp += "."
+
+ s += "### Summary/usage\n %s\n\n" % tmp
+
+ # This is seldom used and will likely be deprecated
+ if "long_help" in v:
+ tmp = v["long_help"]
+
+ s += "### Long help\n %s\n\n" % tmp
+
+ # Extracted from the code in /*? ... ?*/ blocks
+ if "siphon_block" in item["meta"]:
+ sb = item["meta"]["siphon_block"]
+
+ if sb != "":
+ # hack. still needed?
+ sb = sb.replace("\n", "\\n")
+ try:
+ sb = json.loads('"'+sb+'"')
+ s += "### Description\n%s\n\n" % sb
+ except:
+ pass
+
+ # Gives some developer-useful linking
+ if "item" in meta or "function" in v:
+ s += "### Declaration and implementation\n\n"
+
+ if "item" in meta:
+ s += "Declaration: @ref %s (%s:%d)\n\n" % \
+ (meta['item'], meta["file"], int(item["meta"]["line_start"]))
+
+ if "function" in v:
+ s += "Implementation: @ref %s.\n\n" % v["function"]
+
+ return s
+
+
+siphons = {
+ "VLIB_CLI_COMMAND": {
+ "index_sort_key": clicmd_index_sort,
+ "index_header": clicmd_index_header,
+ "index_section": clicmd_index_section,
+ "index_entry": clicmd_index_entry,
+ 'sort_key': clicmd_sort,
+ "header": clicmd_header,
+ "format": clicmd_format,
+ }
+}
+
+
+# PyParsing definition for our struct initializers which look like this:
+# VLIB_CLI_COMMAND (show_sr_tunnel_command, static) = {
+# .path = "show sr tunnel",
+# .short_help = "show sr tunnel [name <sr-tunnel-name>]",
+# .function = show_sr_tunnel_fn,
+#};
+def getMacroInitializerBNF():
+ cs = pp.Forward()
+ ident = pp.Word(pp.alphas + "_", pp.alphas + pp.nums + "_")
+ intNum = pp.Word(pp.nums)
+ hexNum = pp.Literal("0x") + pp.Word(pp.hexnums)
+ octalNum = pp.Literal("0") + pp.Word("01234567")
+ integer = (hexNum | octalNum | intNum) + \
+ pp.Optional(pp.Literal("ULL") | pp.Literal("LL") | pp.Literal("L"))
+ floatNum = pp.Regex(r'\d+(\.\d*)?([eE]\d+)?') + pp.Optional(pp.Literal("f"))
+ char = pp.Literal("'") + pp.Word(pp.printables, exact=1) + pp.Literal("'")
+ arrayIndex = integer | ident
+
+ lbracket = pp.Literal("(").suppress()
+ rbracket = pp.Literal(")").suppress()
+ lbrace = pp.Literal("{").suppress()
+ rbrace = pp.Literal("}").suppress()
+ comma = pp.Literal(",").suppress()
+ equals = pp.Literal("=").suppress()
+ dot = pp.Literal(".").suppress()
+ semicolon = pp.Literal(";").suppress()
+
+ # initializer := { [member = ] (variable | expression | { initializer } ) }
+ typeName = ident
+ varName = ident
+
+ typeSpec = pp.Optional("unsigned") + \
+ pp.oneOf("int long short float double char u8 i8 void") + \
+ pp.Optional(pp.Word("*"), default="")
+ typeCast = pp.Combine( "(" + ( typeSpec | typeName ) + ")" ).suppress()
+
+ string = pp.Combine(pp.OneOrMore(pp.QuotedString(quoteChar='"',
+ escChar='\\', multiline=True)), adjacent=False)
+ literal = pp.Optional(typeCast) + (integer | floatNum | char | string)
+ var = pp.Combine(pp.Optional(typeCast) + varName + pp.Optional("[" + arrayIndex + "]"))
+
+ expr = (literal | var) # TODO
+
+
+ member = pp.Combine(dot + varName + pp.Optional("[" + arrayIndex + "]"))
+ value = (expr | cs)
+
+ entry = pp.Group(pp.Optional(member + equals, default="") + value)
+ entries = (pp.ZeroOrMore(entry + comma) + entry + pp.Optional(comma)) | \
+ (pp.ZeroOrMore(entry + comma))
+
+ cs << (lbrace + entries + rbrace)
+
+ macroName = ident
+ params = pp.Group(pp.ZeroOrMore(expr + comma) + expr)
+ macroParams = lbracket + params + rbracket
+
+ mi = macroName + pp.Optional(macroParams) + equals + pp.Group(cs) + semicolon
+ mi.ignore(pp.cppStyleComment)
+ return mi
+
+
+mi = getMacroInitializerBNF()
+
+# Parse the input file into a more usable dictionary structure
+cmds = {}
+line_num = 0
+line_start = 0
+for filename in args.input:
+ sys.stderr.write("Parsing items in file \"%s\"...\n" % filename)
+ data = None
+ with open(filename, "r") as fd:
+ data = json.load(fd)
+
+ cmds['_global'] = data['global']
+
+ # iterate the items loaded and regroup it
+ for item in data["items"]:
+ try:
+ o = mi.parseString(item['block']).asList()
+ except:
+ sys.stderr.write("Exception parsing item: %s\n%s\n" \
+ % (json.dumps(item, separators=(',', ': '), indent=4),
+ item['block']))
+ raise
+
+ group = item['group']
+ file = item['file']
+ macro = o[0]
+ param = o[1][0]
+
+ if group not in cmds:
+ cmds[group] = {}
+
+ if file not in cmds[group]:
+ cmds[group][file] = {}
+
+ if macro not in cmds[group][file]:
+ cmds[group][file][macro] = {}
+
+ c = {
+ 'params': o[2],
+ 'meta': {},
+ 'value': {},
+ }
+
+ for key in item:
+ if key == 'block':
+ continue
+ c['meta'][key] = item[key]
+
+ for i in c['params']:
+ c['value'][i[0]] = cgi.escape(i[1])
+
+ cmds[group][file][macro][param] = c
+
+
+# Write the header for this siphon type
+cfg = siphons[siphon_map[args.type]]
+sys.stdout.write(cfg["index_header"](cfg))
+contents = ""
+
+def group_sort_key(item):
+ if "index_sort_key" in cfg:
+ return cfg["index_sort_key"](cfg, item, cmds['_global'])
+ return item
+
+# Iterate the dictionary and process it
+for group in sorted(cmds.keys(), key=group_sort_key):
+ if group.startswith('_'):
+ continue
+
+ sys.stderr.write("Processing items in group \"%s\"...\n" % group)
+
+ cfg = siphons[siphon_map[args.type]]
+ md = group.replace("/", "_").replace(".", "_")
+ sys.stdout.write(cfg["index_section"](cfg, group, md))
+
+ if "header" in cfg:
+ dec = cmds['_global']
+ contents += cfg["header"](cfg, group, md, dec)
+
+ for file in sorted(cmds[group].keys()):
+ if group.startswith('_'):
+ continue
+
+ sys.stderr.write("- Processing items in file \"%s\"...\n" % file)
+
+ for macro in sorted(cmds[group][file].keys()):
+ if macro != siphon_map[args.type]:
+ continue
+ sys.stderr.write("-- Processing items in macro \"%s\"...\n" % macro)
+ cfg = siphons[macro]
+
+ meta = {
+ "group": group,
+ "file": file,
+ "macro": macro,
+ "md": md,
+ }
+
+ def item_sort_key(item):
+ if "sort_key" in cfg:
+ return cfg["sort_key"](cfg, meta, cmds[group][file][macro][item])
+ return item
+
+ for param in sorted(cmds[group][file][macro].keys(), key=item_sort_key):
+ sys.stderr.write("--- Processing item \"%s\"...\n" % param)
+
+ meta["item"] = param
+
+ # mangle "md" and the item to make a reference label
+ meta["label"] = "%s___%s" % (meta["md"], param)
+
+ if "index_entry" in cfg:
+ s = cfg["index_entry"](cfg, meta, cmds[group][file][macro][param])
+ sys.stdout.write(s)
+
+ if "format" in cfg:
+ contents += cfg["format"](cfg, meta, cmds[group][file][macro][param])
+
+sys.stdout.write(contents)
+
+# All done
{kind=link}
{kind=link}